

Abstract
Recently, there has been notable success in the field of video editing through the integration of text-image-driven techniques based on diffusion models. However, challenges persist, particularly in handling complex dynamic scenes characterized by substantial pixel variations between consecutive frames. Existing video editing methods struggle with frame inconsistency issues, leading to key content loss and color disruptions in motion.
In our research, we present Fly-A-Video, a pioneering general-purpose video editing framework designed to address these challenges. We leverage a frequency-level frame-consistency diffusion model to generate high-quality, coherent videos. Our approach involves two key innovations:
- Frequency Optimization Module: We propose the incorporation of a discrete cosine transform (DCT) in the diffusion model to establish a frequency optimization module. This module decomposes temporal features of the video into distinct frequency components. Notably, the low-frequency component encapsulates crucial content features, while the high-frequency component captures differences between adjacent frames. By reinforcing the significance of low-frequency components and mitigating the impact of high-frequency ones, we enhance frame consistency in video sequence generation.
- Frequency-Level Attention Mechanism: Additionally, we introduce a straightforward frequency-level attention mechanism. This mechanism calculates correlations using frequency domain features of the current frame and all frames in the video, contributing to improved frame consistency during video editing.
We conducted a thorough evaluation of our approach across diverse video datasets, showcasing its superior performance in terms of visual coherence quality, diversity, and textual content consistency compared to existing methods.
Introduction
Method
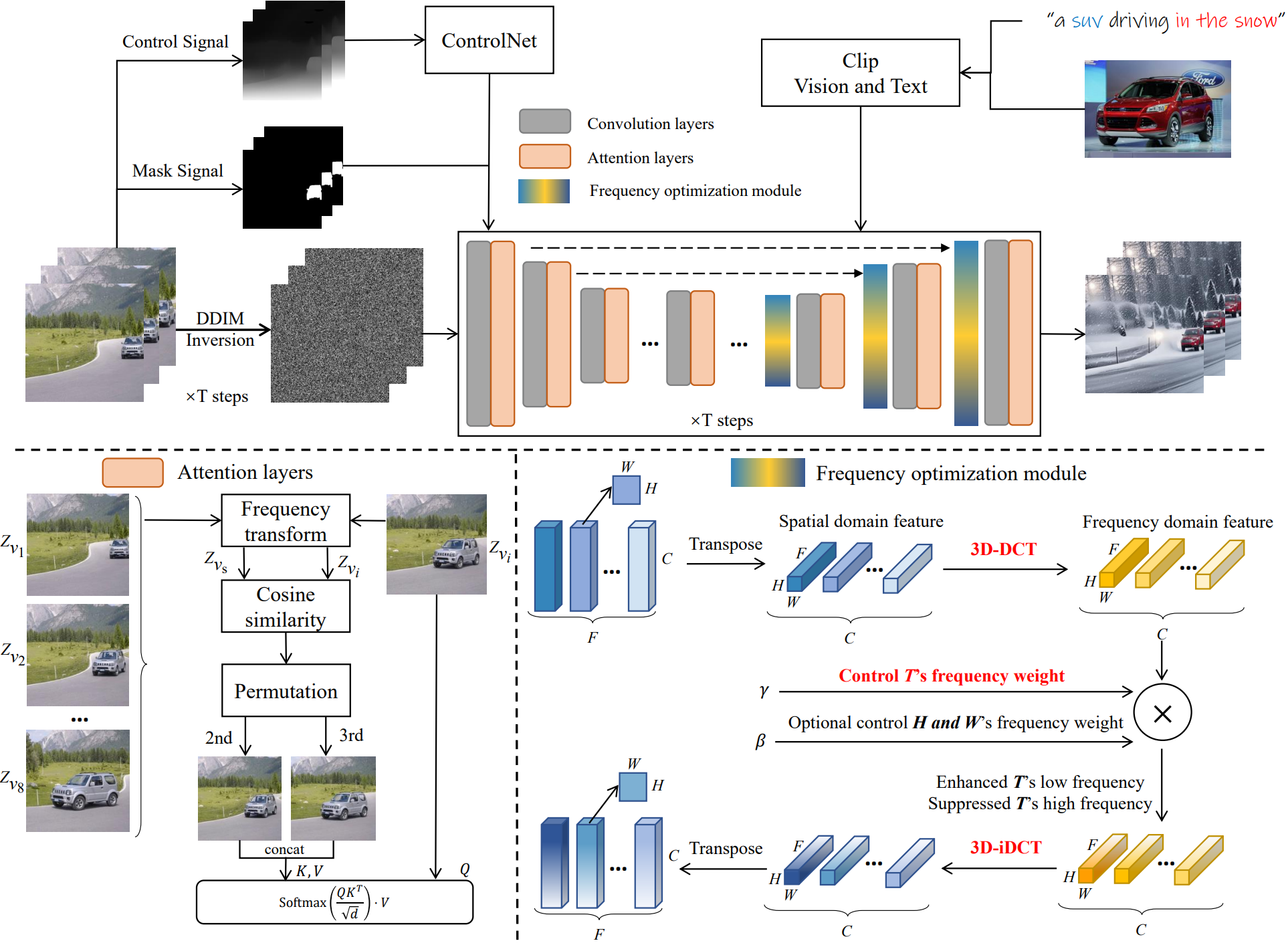
Fly-A-Video: Given a text and image-video pair (e.g., "an suv driving in the snow”) as input, our method leverages the frame-consistency diffusion models for general editing. We mainly modify the Attention layers and introduce the Frequency optimization module.
Results
Text-driven Video Editing


Image-driven Video Editing




General Video Editing
 |
 |
 |
|---|---|---|
"a jeep wrangler driving down a mountain road." |
"an suv driving in the desert." |
 |
 |
 |
|---|---|---|
"A duck swimming in a pond." |
"A flamingo swimming in a lake." |
 |
 |
 |
|---|---|---|
"a polar bear walking across the snow." |
"a bear walking across the desert." |
 |
 |
 |
|---|---|---|
"an eagle flying over the water." |
"a parrot flying over the grass." |
 |
 |
 |
|---|---|---|
"a woman doing a dance routine." |
"a man doing a dance routine in the snow." |
General Video Editing with Style
|
|
 |
|---|---|---|
"a jeep wrangler driving down a mountain road." |
"an suv driving in the desert, comic style." |
|
|
 |
|---|---|---|
"A duck swimming in a pond." |
"A flamingo swimming in a lake, anime style." |
|
|
 |
|---|---|---|
"a polar bear walking across the snow." |
"a bear walking across the desert, anime style." |
|
|
 |
|---|---|---|
"an eagle flying over the water." |
"a parrot flying over the grass, Van Gogh style." |
|
|
 |
|---|---|---|
"a woman doing a dance routine." |
"a man doing a dance routine in the snow, Van Gogh style." |
Qualitative comparison with other methods
Text-driven Video Editing
|
 |
 |
 |
|---|---|---|---|
"a jeep wrangler driving down a mountain road." -- Source Video |
"a red suv driving in the snow." -- Tune-A-Video CILP-T: 31.13 FC: 94.19 |
"a red suv driving in the snow." -- Tokenflow CILP-T: 30.40 FC: 95.07 |
"a red suv driving in the snow." -- Fly-A-Video CILP-T: 32.20 FC: 96.09 |
 |
 |
 |
 |
|---|---|---|---|
"a seagull standing in the water." -- Source Video |
"a yellow parrot standing in the grass." -- Tune-A-Video CILP-T: 28.17 FC: 95.39 |
"a yellow parrot standing in the grass." -- Tokenflow CILP-T: 33.52 FC: 96.14 |
"a yellow parrot standing in the grass." -- Fly-A-Video CILP-T: 34.79 FC: 96.95 |
 |
 |
 |
 |
|---|---|---|---|
"A bird flying in the sky." -- Source Video |
"an owl flying on the mountain, van gogh style." -- Tune-A-Video CILP-T: 25.15 FC: 93.58 |
"an owl flying on the mountain, van gogh style." -- Tokenflow CILP-T: 27.27 FC: 95.70 |
"an owl flying on the mountain, van gogh style." -- Fly-A-Video CILP-T: 37.04 FC: 96.09 |
General Video Editing
|
 |
 |
 |
|---|---|---|---|
"a jeep wrangler driving down a mountain road." -- Source Video |
"a red suv driving in the snow." -- Make-A-Protagonist CILP-T: 29.17 FC: 93.41 |
"a red suv driving in the snow." -- Fly-A-Video CILP-T: 29.88 FC: 94.97 |
|
 |
 |
 |
|---|---|---|---|
"a yellow parrot standing in the grass." -- Source Video |
"a yellow parrot standing in the grass." -- Make-A-Protagonist CILP-T: 33.89 FC: 96.00 |
"a yellow parrot standing in the grass." -- Fly-A-Video CILP-T: 33.91 FC: 96.53 |
|
 |
 |
 |
|---|---|---|---|
"A bird flying in the sky." -- Source Video |
"an owl flying on the mountain, van gogh style." -- Make-A-Protagonist CILP-T: 38.50 FC: 92.09 |
"an owl flying on the mountain, van gogh style." -- Fly-A-Video CILP-T: 38.53 FC: 94.68 |
Ablation study
W/o Frequence Optimization Module
|
|
|
 |
|
|---|---|---|---|---|
"a jeep wrangler driving down a mountain road." -- Source Video |
"a red suv driving in the snow." -- Make-A-Protagonist CILP-T: 29.17 FC: 93.41 |
"a red suv driving in the snow." -- W/o Fre Opt Module CILP-T: 29.32 FC: 94.38 |
"a red suv driving in the snow." -- Fly-A-Video CILP-T: 29.88 FC: 94.97 |
 |
 |
 |
 |
 |
|---|---|---|---|---|
"A man is playing basketball." -- Source Video |
"A man is playing a basketball on the moon." -- Make-A-Protagonist CILP-T: 29.83 FC: 88.42 |
"A man is playing a basketball on the moon." -- W/o Fre Opt Module CILP-T: 33.52 FC: 93.31 |
"A man is playing a basketball on the moon." -- Fly-A-Video CILP-T: 33.71 FC: 93.7 |
 |
 |
 |
 |
 |
|---|---|---|---|---|
"a capybara walking in a zoo" -- Source Video |
"a hippo walking on the grass." -- Make-A-Protagonist CILP-T: 32.29 FC: 95.01 |
"a hippo walking on the grass." -- W/o Fre Opt Module CILP-T: 31.74 FC: 95.75 |
"a hippo walking on the grass." -- Fly-A-Video CILP-T: 33.30 FC: 96.87 |
 |
 |
 |
 |
 |
|---|---|---|---|---|
"a wolf walking through a field." -- Source Video |
"A dog walking on the road." -- Make-A-Protagonist CILP-T: 33.25 FC: 93.99 |
"A dog walking on the road." -- W/o Fre Opt Module CILP-T: 32.91 FC: 96.02 |
"A dog walking on the road." -- Fly-A-Video CILP-T: 33.35 FC: 95.98 |
W/o Attention Layers
|
|
|
 |
|
|---|---|---|---|---|
"a jeep wrangler driving down a mountain road." -- Source Video |
"a red suv driving in the snow." -- Make-A-Protagonist CILP-T: 29.17 FC: 93.41 |
"a red suv driving in the snow." -- W/o Attn Layers CILP-T: 29.49 FC: 93.99 |
"a red suv driving in the snow." -- Fly-A-Video CILP-T: 29.88 FC: 94.97 |
|
|
|
 |
|
|---|---|---|---|---|
"A man is playing basketball." -- Source Video |
"A man is playing a basketball on the moon." -- Make-A-Protagonist CILP-T: 29.83 FC: 88.42 |
"A man is playing a basketball on the moon." -- W/o Attn Layers CILP-T: 31.32 FC: 90.62 |
"A man is playing a basketball on the moon." -- Fly-A-Video CILP-T: 33.71 FC: 93.70 |
|
|
|
 |
|
|---|---|---|---|---|
"a capybara walking in a zoo" -- Source Video |
"a hippo walking on the grass." -- Make-A-Protagonist CILP-T: 32.29 FC: 95.01 |
"a hippo walking on the grass." -- W/o Attn Layers CILP-T: 31.96 FC: 95.21 |
"a hippo walking on the grass." -- Fly-A-Video CILP-T: 33.30 FC: 96.87 |
|
|
|
 |
|
|---|---|---|---|---|
"a wolf walking through a field." -- Source Video |
"A dog walking on the road." -- Make-A-Protagonist CILP-T: 33.25 FC: 93.99 |
"A dog walking on the road." -- W/o Attn Layers CILP-T: 33.30 FC: 95.21 |
"A dog walking on the road." -- Fly-A-Video CILP-T: 33.35 FC: 95.98 |
Comparison of different C values
 |
 |
 |
 |
 |
|---|---|---|---|---|
"A lion walking on the grass." -- Source Video |
"A wolf walking through ice sheet." -- c=0.6 |
"A wolf walking through ice sheet." -- c=1.0 |
"A wolf walking through ice sheet." -- c=1.4 |
|
|
 |
|
 |
|---|---|---|---|---|
"A lion walking on the grass." -- Source Video |
"A wolf walking through ice sheet." -- c=0.8 |
"A wolf walking through ice sheet." -- c=1.0 |
"A wolf walking through ice sheet." -- c=1.2 |
 |
 |
 |
 |
 |
|---|---|---|---|---|
"A sheep walking on the grass." -- Source Video |
"A horse grazing on a ice lake." -- c=0.6 |
"A horse grazing on a ice lake." -- c=1.0 |
"A horse grazing on a ice lake." -- c=1.4 |
|
|
 |
|
 |
|---|---|---|---|---|
"A sheep walking on the grass." -- Source Video |
"A horse grazing on a ice lake." -- c=0.8 |
"A horse grazing on a ice lake." -- c=1.0 |
"A horse grazing on a ice lake." -- c=1.2 |